Another one of OpenAI’s lead safety researchers, Lilian Weng, announced on Friday she is departing the startup. Weng served as VP of research and safety since August, and before that, was the head of the OpenAI’s safety systems team. In a post on X, Weng said that “after 7 years at OpenAI, I feel ready […]
Now that the election is over, the dissection can begin. As this is the first election in which AI chatbots played a significant part of voters’ information diets, even approximate numbers are interesting to think about. For instance, OpenAI has stated that it told around 2 million users of ChatGPT to go look somewhere else. […]
Anthropic has announced a partnership with Palantir and Amazon Web Services to bring its Claude AI models to unspecified US intelligence and defense agencies. Claude, a family of AI language models similar to those that power ChatGPT, will work within Palantir's platform using AWS hosting to process and analyze data. But some critics have called out the deal as contradictory to Anthropic's widely-publicized "AI safety" aims.
The partnership makes Claude available within Palantir's Impact Level 6 environment (IL6), a defense-accredited system that handles data critical to national security up to the "secret" classification level. This move follows a broader trend of AI companies seeking defense contracts, with Meta offering its Llama models to defense partners and OpenAI pursuing closer ties with the Defense Department.
On Wednesday, OpenAI CEO Sam Altman merely tweeted "chat.com," announcing that the company had acquired the short domain name, which now points to the company's ChatGPT AI assistant when visited in a web browser. As of Thursday morning, "chatgpt.com" still hosts the chatbot, with the new domain serving as a redirect.
The new domain name comes with an interesting backstory that reveals a multimillion-dollar transaction. HubSpot founder and CTO Dharmesh Shah purchased chat.com for $15.5 million in early 2023, The Verge reports. Shah sold the domain to OpenAI for an undisclosed amount, though he confirmed on X that he "doesn't like profiting off of people he considers friends" and that he received payment in company shares by revealing he is "now an investor in OpenAI."
As The Verge's Kylie Robison points out, Shah originally bought the domain to promote conversational interfaces. "The reason I bought chat.com is simple: I think Chat-based UX (#ChatUX) is the next big thing in software. Communicating with computers/software through a natural language interface is much more intuitive. This is made possible by Generative A.I.," Shah wrote in a LinkedIn post during his brief ownership.
OpenAI bought Chat.com, adding to its collection of high-profile domain names. As of this morning, Chat.com now redirects to OpenAI’s AI-powered chatbot, ChatGPT. An OpenAI spokesperson confirmed the acquisition via email. Chat.com is one of the older domains on the web, having been registered in September 1996. Last year, it was reported that HubSpot co-founder […]
The large language model-based coding assistant GitHub Copilot will switch from exclusively using OpenAI's GPT models to a multi-model approach over the coming weeks, GitHub CEO Thomas Dohmke announced in a post on GitHub's blog.
First, Anthropic's Claude 3.5 Sonnet will roll out to Copilot Chat's web and VS Code interfaces over the next few weeks. Google's Gemini 1.5 Pro will come a bit later.
Additionally, GitHub will soon add support for a wider range of OpenAI models, including GPT o1-preview and o1-mini, which are intended to be stronger at advanced reasoning than GPT-4, which Copilot has used until now. Developers will be able to switch between the models (even mid-conversation) to tailor the model to fit their needs—and organizations will be able to choose which models will be usable by team members.
ChatGPT, OpenAI’s text-generating AI chatbot, has taken the world by storm since its launch in November 2022. What started as a tool to hyper-charge productivity through writing essays and code with short text prompts has evolved into a behemoth used by more than 92% of Fortune 500 companies. That growth has propelled OpenAI itself into […]
OpenAI is reportedly working with TSMC and Broadcom to build an in-house AI chip — and beginning to use AMD chips alongside Nvidia’s to train its AI. Reuters reports that OpenAI has — at least for now — abandoned plans to establish a network of factories for chip manufacturing. Instead, the company will focus on […]
On Saturday, an Associated Press investigation revealed that OpenAI's Whisper transcription tool creates fabricated text in medical and business settings despite warnings against such use. The AP interviewed more than 12 software engineers, developers, and researchers who found the model regularly invents text that speakers never said, a phenomenon often called a "confabulation" or "hallucination" in the AI field.
Upon its release in 2022, OpenAI claimed that Whisper approached "human level robustness" in audio transcription accuracy. However, a University of Michigan researcher told the AP that Whisper created false text in 80 percent of public meeting transcripts examined. Another developer, unnamed in the AP report, claimed to have found invented content in almost all of his 26,000 test transcriptions.
The fabrications pose particular risks in health care settings. Despite OpenAI's warnings against using Whisper for "high-risk domains," over 30,000 medical workers now use Whisper-based tools to transcribe patient visits, according to the AP report. The Mankato Clinic in Minnesota and Children's Hospital Los Angeles count among 40 health systems using a Whisper-powered AI copilot service from medical tech company Nabla that is fine-tuned on medical terminology.
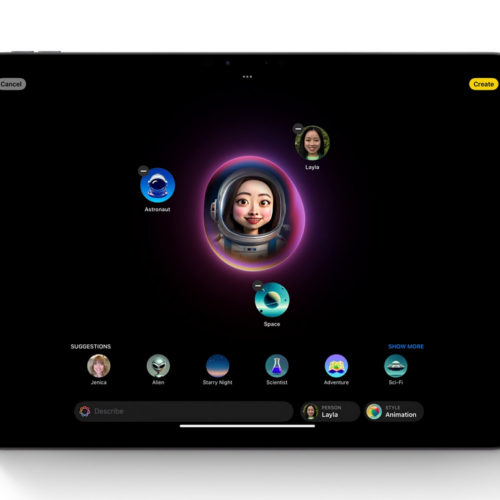
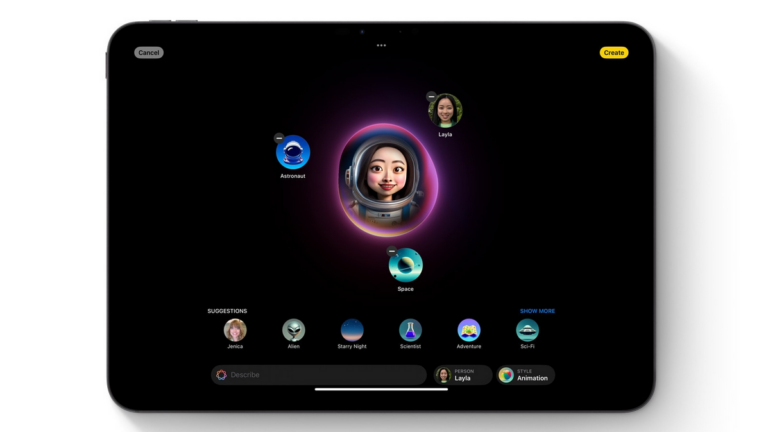
Today, Apple released the first developer beta of iOS 18.2 for supported devices. This beta release marks the first time several key AI features that Apple teased at its developer conference this June are available.
Apple is marketing a wide range of generative AI features under the banner "Apple Intelligence." Initially, Apple Intelligence was planned to release as part of iOS 18, but some features slipped to iOS 18.1, others to iOS 18.2, and a few still to future undisclosed software updates.
iOS 18.1 has been in beta for a while and includes improvements to Siri, generative writing tools that help with rewriting or proofreading, smart replies for Messages, and notification summaries. That update is expected to reach the public next week.
Emteq Labs wants eyewear to be the next frontier of wearable health technology.
The Brighton, England-based company introduced today its emotion-sensing eyewear, Sense. The glasses contain nine optical sensors distributed across the rims that detect subtle changes in facial expression with more than 93 percent accuracy when paired with Emteq’s current software. “If your face moves, we can capture it,” says Steen Strand, whose appointment as Emteq’s new CEO was also announced today. With that detailed data, “you can really start to decode all kinds of things.” The continuous data could help people uncover patterns in their behavior and mood, similar to an activity or sleep tracker.
Emteq is now aiming to take its tech out of laboratory settings with real-world applications. The company is currently producing a small number of Sense glasses, and they’ll be available to commercial partners in December.
The announcement comes just weeks after Meta and Snap each unveiled augmented reality glasses that remain in development. These glasses are “far from ready,” says Strand, who led the augmented reality eyewear division while working at Snap from 2018 to 2022. “In the meantime, we can serve up lightweight eyewear that we believe can deliver some really cool health benefits.”
Fly Vision Vectors
While current augmented reality (AR) headsets have large battery packs to power the devices, glasses require a lightweight design. “Every little bit of power, every bit of weight, becomes critically important,” says Strand. The current version of Sense weighs 62 grams, slightly heavier than the Ray-Ban Meta smart glasses, which weigh in at about 50 grams.
Because of the weight constraints, Emteq couldn’t use the power-hungry cameras typically used in headsets. With cameras, motion is detected by looking at how pixels change between consecutive images. The method is effective, but captures a lot of redundant information and uses more power. The eyewear’s engineers instead opted for optical sensors that efficiently capture vectors when points on the face move due to the underlying muscles. These sensors were inspired by the efficiency of fly vision. “Flies are incredibly efficient at measuring motion,” says Emteq founder and CSO Charles Nduka. “That’s why you can’t swat the bloody things. They have a very high sample rate internally.”
Sense glasses can capture data as often as 6,000 times per second. The vector-based approach also adds a third dimension to a typical camera’s 2D view of pixels in a single plane.
These sensors look for activation of facial muscles, and the area around the eyes is an ideal spot. While it’s easy to suppress or force a smile, the upper half of our face tends to have more involuntary responses, explains Nduka, who also works as a plastic surgeon in the United Kingdom. However, the glasses can also collect information about the mouth by monitoring the cheek muscles that control jaw movements, conveniently located near the lower rim of a pair of glasses. The data collected is then transmitted from the glasses to pass through Emteq’s algorithms in order to translate the vector data into usable information.
In addition to interpreting facial expressions, Sense can be used to track food intake, an application discovered by accident when one of Emteq’s developers was wearing the glasses while eating breakfast. By monitoring jaw movement, the glasses detect when a user chews and how quickly they eat. Meanwhile, a downward-facing camera takes a photo to log the food, and uses a large language model to determine what’s in the photo, effectively making food logging a passive activity. Currently, Emteq is using an instance of OpenAI’s GPT-4 large language model to accomplish this, but the company has plans to create their own algorithm in the future. Other applications, including monitoring physical activity and posture, are also in development.
One Platform, Many Uses
Nduka believes Emteq’s glasses represent a “fundamental technology,” similar to how the accelerometer is used for a host of applications in smartphones, including managing screen orientation, tracking activity, and even revealing infrastructure damage.
Similarly, Emteq has chosen to develop the technology as a general facial data platform for a range of uses. “If we went deep on just one, it means that all the other opportunities that can be helped—especially some of those rarer use cases—they’d all be delayed,” says Nduka. For example, Nduka is passionate about developing a tool to help those with facial paralysis. But a specialized device for those patients would have high unit costs and be unaffordable for the target user. Allowing more companies to use Emteq’s intellectual property and algorithms will bring down cost.
In this buckshot approach, the general target for Sense’s potential use cases is health applications. “If you look at the history of wearables, health has been the primary driver,” says Strand. The same may be true for eyewear, and he says there’s potential for diet and emotional data to be “the next pillar of health” after sleep and physical activity.
How the data is delivered is still to be determined. In some applications, it could be used to provide real-time feedback—for instance, vibrating to remind the user to slow down eating. Or, it could be used by health professionals only to collect a week’s worth of at-home data for patients with mental health conditions, which Nduka notes largely lack objective measures. (As a medical device for treatment of diagnosed conditions, Sense would have to go through a more intensive regulatory process.) While some users are hungry for more data, others may require a “much more gentle, qualitative approach,” says Strand. Emteq plans to work with expert providers to appropriately package information for users.
Interpreting the data must be done with care, says Vivian Genaro Motti, an associate professor at George Mason University who leads the Human-Centric Design Lab. What expressions mean may vary based on cultural and demographic factors, and “we need to take into account that people sometimes respond to emotions in different ways,” Motti says. With little regulation of wearable devices, she says it’s also important to ensure privacy and protect user data. But Motti raises these concerns because there is a promising potential for the device. “If this is widespread, it’s important that we think carefully about the implications.”
Privacy is also a concern to Edward Savonov, a professor of electrical and computer engineering at the University of Alabama, who developed a similar device for dietary tracking in his lab. Having a camera mounted on Emteq’s glasses could pose issues, both for the privacy of those around a user and a user’s own personal information. Many people eat in front of their computer or cell phone, so sensitive data may be in view.
For technology like Sense to be adopted, Sazonov says questions about usability and privacy concerns must first be answered. “Eyewear-based technology has potential for a great future—if we get it right.”
Maybe you’ve read about Gary Marcus’s testimony before the Senate in May of 2023, when he sat next to Sam Altman and called for strict regulation of Altman’s company, OpenAI, as well as the other tech companies that were suddenly all-in on generative AI. Maybe you’ve caught some of his arguments on Twitter with Geoffrey Hinton and Yann LeCun, two of the so-called “godfathers of AI.” One way or another, most people who are paying attention to artificial intelligence today know Gary Marcus’s name, and know that he is not happy with the current state of AI.
He lays out his concerns in full in his new book, Taming Silicon Valley: How We Can Ensure That AI Works for Us, which was published today by MIT Press. Marcus goes through the immediate dangers posed by generative AI, which include things like mass-produced disinformation, the easy creation of deepfake pornography, and the theft of creative intellectual property to train new models (he doesn’t include an AI apocalypse as a danger, he’s not a doomer). He also takes issue with how Silicon Valley has manipulated public opinion and government policy, and explains his ideas for regulating AI companies.
Marcus studied cognitive science under the legendary Steven Pinker, was a professor at New York University for many years, and co-founded two AI companies, Geometric Intelligence and Robust.AI. He spoke with IEEE Spectrum about his path to this point.
What was your first introduction to AI?
Gary MarcusBen Wong
Gary Marcus: Well, I started coding when I was eight years old. One of the reasons I was able to skip the last two years of high school was because I wrote a Latin-to-English translator in the programming language Logo on my Commodore 64. So I was already, by the time I was 16, in college and working on AI and cognitive science.
So you were already interested in AI, but you studied cognitive science both in undergrad and for your Ph.D. at MIT.
Marcus: Part of why I went into cognitive science is I thought maybe if I understood how people think, it might lead to new approaches to AI. I suspect we need to take a broad view of how the human mind works if we’re to build really advanced AI. As a scientist and a philosopher, I would say it’s still unknown how we will build artificial general intelligence or even just trustworthy general AI. But we have not been able to do that with these big statistical models, and we have given them a huge chance. There’s basically been $75 billion spent on generative AI, another $100 billion on driverless cars. And neither of them has really yielded stable AI that we can trust. We don’t know for sure what we need to do, but we have very good reason to think that merely scaling things up will not work. The current approach keeps coming up against the same problems over and over again.
What do you see as the main problems it keeps coming up against?
Marcus: Number one is hallucinations. These systems smear together a lot of words, and they come up with things that are true sometimes and not others. Like saying that I have a pet chicken named Henrietta is just not true. And they do this a lot. We’ve seen this play out, for example, in lawyers writing briefs with made-up cases.
Second, their reasoning is very poor. My favorite examples lately are these river-crossing word problems where you have a man and a cabbage and a wolf and a goat that have to get across. The system has a lot of memorized examples, but it doesn’t really understand what’s going on. If you give it a simpler problem, like one Doug Hofstadter sent to me, like: “A man and a woman have a boat and want to get across the river. What do they do?” It comes up with this crazy solution where the man goes across the river, leaves the boat there, swims back, something or other happens.
Sometimes he brings a cabbage along, just for fun.
Marcus: So those are boneheaded errors of reasoning where there’s something obviously amiss. Every time we point these errors out somebody says, “Yeah, but we’ll get more data. We’ll get it fixed.” Well, I’ve been hearing that for almost 30 years. And although there is some progress, the core problems have not changed.
Let’s go back to 2014 when you founded your first AI company, Geometric Intelligence. At that time, I imagine you were feeling more bullish on AI?
Marcus: Yeah, I was a lot more bullish. I was not only more bullish on the technical side. I was also more bullish about people using AI for good. AI used to feel like a small research community of people that really wanted to help the world.
So when did the disillusionment and doubt creep in?
Marcus: In 2018 I already thought deep learning was getting overhyped. That year I wrote this piece called “Deep Learning, a Critical Appraisal,” which Yann LeCun really hated at the time. I already wasn’t happy with this approach and I didn’t think it was likely to succeed. But that’s not the same as being disillusioned, right?
Then when large language models became popular [around 2019], I immediately thought they were a bad idea. I just thought this is the wrong way to pursue AI from a philosophical and technical perspective. And it became clear that the media and some people in machine learning were getting seduced by hype. That bothered me. So I was writing pieces about GPT-3 [an early version of OpenAI's large language model] being a bullshit artist in 2020. As a scientist, I was pretty disappointed in the field at that point. And then things got much worse when ChatGPT came out in 2022, and most of the world lost all perspective. I began to get more and more concerned about misinformation and how large language models were going to potentiate that.
You’ve been concerned not just about the startups, but also the big entrenched tech companies that jumped on the generative AI bandwagon, right? Like Microsoft, which has partnered with OpenAI?
Marcus: The last straw that made me move from doing research in AI to working on policy was when it became clear that Microsoft was going to race ahead no matter what. That was very different from 2016 when they released [an early chatbot named] Tay. It was bad, they took it off the market 12 hours later, and then Brad Smith wrote a book about responsible AI and what they had learned. But by the end of the month of February 2023, it was clear that Microsoft had really changed how they were thinking about this. And then they had this ridiculous “Sparks of AGI” paper, which I think was the ultimate in hype. And they didn’t take down Sydney after the crazy Kevin Roose conversation where [the chatbot] Sydney told him to get a divorce and all this stuff. It just became clear to me that the mood and the values of Silicon Valley had really changed, and not in a good way.
I also became disillusioned with the U.S. government. I think the Biden administration did a good job with its executive order. But it became clear that the Senate was not going to take the action that it needed. I spoke at the Senate in May 2023. At the time, I felt like both parties recognized that we can’t just leave all this to self-regulation. And then I became disillusioned [with Congress] over the course of the last year, and that’s what led to writing this book.
You talk a lot about the risks inherent in today’s generative AI technology. But then you also say, “It doesn’t work very well.” Are those two views coherent?
Marcus: There was a headline: “Gary Marcus Used to Call AI Stupid, Now He Calls It Dangerous.” The implication was that those two things can’t coexist. But in fact, they do coexist. I still think gen AI is stupid, and certainly cannot be trusted or counted on. And yet it is dangerous. And some of the danger actually stems from its stupidity. So for example, it’s not well-grounded in the world, so it’s easy for a bad actor to manipulate it into saying all kinds of garbage. Now, there might be a future AI that might be dangerous for a different reason, because it’s so smart and wily that it outfoxes the humans. But that’s not the current state of affairs.
Marcus: Let’s clarify: I don’t think generative AI is going to disappear. For some purposes, it is a fine method. You want to build autocomplete, it is the best method ever invented. But there’s a financial bubble because people are valuing AI companies as if they’re going to solve artificial general intelligence. In my view, it’s not realistic. I don’t think we’re anywhere near AGI. So then you’re left with, “Okay, what can you do with generative AI?”
Last year, because Sam Altman was such a good salesman, everybody fantasized that we were about to have AGI and that you could use this tool in every aspect of every corporation. And a whole bunch of companies spent a bunch of money testing generative AI out on all kinds of different things. So they spent 2023 doing that. And then what you’ve seen in 2024 are reports where researchers go to the users of Microsoft’s Copilot—not the coding tool, but the more general AI tool—and they’re like, “Yeah, it doesn’t really work that well.” There’s been a lot of reviews like that this last year.
The reality is, right now, the gen AI companies are actually losing money. OpenAI had an operating loss of something like $5 billion last year. Maybe you can sell $2 billion worth of gen AI to people who are experimenting. But unless they adopt it on a permanent basis and pay you a lot more money, it’s not going to work. I started calling OpenAI the possible WeWork of AI after it was valued at $86 billion. The math just didn’t make sense to me.
What would it take to convince you that you’re wrong? What would be the head-spinning moment?
Marcus: Well, I’ve made a lot of different claims, and all of them could be wrong. On the technical side, if someone could get a pure large language model to not hallucinate and to reason reliably all the time, I would be wrong about that very core claim that I have made about how these things work. So that would be one way of refuting me. It hasn’t happened yet, but it’s at least logically possible.
On the financial side, I could easily be wrong. But the thing about bubbles is that they’re mostly a function of psychology. Do I think the market is rational? No. So even if the stuff doesn’t make money for the next five years, people could keep pouring money into it.
The place that I’d like to prove me wrong is the U.S. Senate. They could get their act together, right? I’m running around saying, “They’re not moving fast enough,” but I would love to be proven wrong on that. In the book, I have a list of the 12 biggest risks of generative AI. If the Senate passed something that actually addressed all 12, then my cynicism would have been mislaid. I would feel like I’d wasted a year writing the book, and I would be very, very happy.
Misschien heb je hem ooit wel gezien: de film Her, over een AI die een relatie krijgt met een man. In de toekomst kun je ook in het echt met de stem van de AI praten. Tenminste, dat is wat OpenAI bedacht had.Vorig jaar introduceerde het bedrijf, dat ChatGPT maakte, een spraakassistent met een stem die geïnspireerd lijkt op die van Scarlett Johansson, die in de film achter de stem zat. Maar wat blijkt: Scarlett Johansson heeft daar helemaal geen toestemming voor gegeven.
De stem Sky bestaat al sinds vorig jaar, maar kreeg bij een demo vorige week meer aandacht. Daarbij werd getoond hoe de spraakassistent een verhaaltje voor het slapengaan vertelde. De AI begint met een vrouwelijke stem, die verdacht veel lijkt op de stem van de AI in Her, die dus door Johansson werd ingesproken. Die gedachte werd kracht bijgezet door een bericht van OpenAI-ceo Sam Altmen: op X plaatste hij het woord ‘her’. En eerder vertelde hij als dat Her zijn favoriete film is.
Hoewel OpenAI al vrij snel benadrukte dat de spraakassistent niet ontworpen is om als Johansson te klinken, ontstond in de afgelopen dagen toch ophef. Op 20 mei werd bekend dat de stem tijdelijk offline wordt gehaald, omdat er veel vragen werden gesteld over Sky, aldus The Verge. Daarbij benadrukte het bedrijf dat Sky niet op Johansson moet lijken. “We vinden dat AI-stemmen niet expres de unieke stem van een beroemdheid moet nadoen”, zegt het bedrijf. “Sky’s stem is geen imitatie van Scarlett Johansson, maar is van een actrice die haar eigen stem gebruikt.”
Scarlett Johansson boos op OpenAI
Inmiddels blijkt echter dat er wat meer achter het verhaal zit. Johansson zelf heeft ondertussen gereageerd met een verklaring en stelt dat OpenAI haar benaderd had om de stem in te spreken. Dat verzoek wees ze af, waarop dus alsnog een stem verscheen die precies als Johansson zelf klinkt. Tegenover NPR zegt ze dat OpenAI haar twee dagen voor de demo verscheen opnieuw benaderde, met de vraag of ze het verzoek wilde heroverwegen. Nog voor er überhaupt een gesprek had plaatsgevonden, was de demo al verschenen en merkte Johansson dus dat Sky op haar lijkt.
“Ik was geshockeerd, woedend en kon niet geloven dat Altman een stem zou maken die zo vergelijkbaar is met de mijne dat mijn naaste vrienden en nieuwsmedia het verschil niet konden horen”, aldus Johansson. Zeker nu er zoveel misinformatie op het internet rondgaat, baart dat haar zorgen. Ondertussen hebben haar advocaten twee brieven naar OpenAI gestuurd, waarin ze vragen om een gedetailleerde beschrijving van het ontwikkelproces van Sky.
Sam Altman ontkent de aantijgingen ondertussen. Hij stelt dat de stemacteur achter Sky al gecast was voor er überhaupt ooit contact was gelegd met Johansson. “Uit respect voor Johansson hebben we het gebruik van Sky’s stem in onze producten gepauzeerd. Het spijt ons dat we niet beter gecommuniceerd hebben”, aldus de ceo.
OpenAI vs. auteursrechten
Het is niet de eerste keer dat OpenAI in opspraak komt na boze eigenaren van rechten. Eerder werden al rechtszaken aangespannen – waaronder door The New York Times – waarin het bedrijf samen met Microsoft beschuldigd wordt van het schenden van auteursrechten. Het AI-bedrijf zou zonder toestemming artikelen van de krant hebben gebruikt om zijn AI-systemen te trainen. Maar op die artikelen rust auteursrecht, dus dat mag niet zomaar. Diverse schrijvers beklaagden zich over hetzelfde probleem: ook hun werk zou zonder toestemming door het bedrijf gebruikt zijn om de systemen te trainen.











 Gary MarcusBen Wong
Gary MarcusBen Wong

