If you haven't noticed by now, Big Tech companies have been making plans to invest in the infrastructure necessary to deliver generative AI products like ChatGPT (and beyond) to hundreds of millions of people around the world. That push involves building more AI-accelerating chips, more data centers, and even new nuclear plants to power those data centers, in some cases.
Along those lines, Microsoft, BlackRock, Global Infrastructure Partners (GIP), and MGX announced a massive new AI investment partnership on Tuesday called the Global AI Infrastructure Investment Partnership (GAIIP). The partnership initially aims to raise $30 billion in private equity capital, which could later turn into $100 billion in total investment when including debt financing.
The group will invest in data centers and supporting power infrastructure for AI development. "The capital spending needed for AI infrastructure and the new energy to power it goes beyond what any single company or government can finance," Microsoft President Brad Smith said in a statement.
On Wednesday, AI video synthesis firm Runway and entertainment company Lionsgate announced a partnership to create a new AI model trained on Lionsgate's vast film and TV library. The deal will feed Runway legally clear training data and will also reportedly provide Lionsgate with tools to enhance content creation while potentially reducing production costs.
Lionsgate, known for franchises like John Wick and The Hunger Games, sees AI as a way to boost efficiency in content production. Michael Burns, Lionsgate's vice chair, stated in a press release that AI could help develop "cutting edge, capital efficient content creation opportunities." He added that some filmmakers have shown enthusiasm about potential applications in pre- and post-production processes.
Runway plans to develop a custom AI model using Lionsgate's proprietary content portfolio. The model will be exclusive to Lionsgate Studios, allowing filmmakers, directors, and creative staff to augment their work. While specifics remain unclear, the partnership marks the first major collaboration between Runway and a Hollywood studio.
Given the flood of photorealistic AI-generated images washing over social media networks like X and Facebook these days, we're seemingly entering a new age of media skepticism: the era of what I'm calling "deep doubt." While questioning the authenticity of digital content stretches back decades—and analog media long before that—easy access to tools that generate convincing fake content has led to a new wave of liars using AI-generated scenes to deny real documentary evidence. Along the way, people's existing skepticism toward online content from strangers may be reaching new heights.
Deep doubt is skepticism of real media that stems from the existence of generative AI. This manifests as broad public skepticism toward the veracity of media artifacts, which in turn leads to a notable consequence: People can now more credibly claim that real events did not happen and suggest that documentary evidence was fabricated using AI tools.
The concept behind "deep doubt" isn't new, but its real-world impact is becoming increasingly apparent. Since the term "deepfake" first surfaced in 2017, we've seen a rapid evolution in AI-generated media capabilities. This has led to recent examples of deep doubt in action, such as conspiracy theorists claiming that President Joe Biden has been replaced by an AI-powered hologram and former President Donald Trump's baseless accusation in August that Vice President Kamala Harris used AI to fake crowd sizes at her rallies. And on Friday, Trump cried "AI" again at a photo of him with E. Jean Carroll, a writer who successfully sued him for sexual assault, that contradicts his claim of never having met her.
Enlarge/ Under C2PA, this stock image would be labeled as a real photograph if the camera used to take it, and the toolchain for retouching it, supported the C2PA. But even as a real photo, does it actually represent reality, and is there a technological solution to that problem? (credit: Smile via Getty Images)
On Tuesday, Google announced plans to implement content authentication technology across its products to help users distinguish between human-created and AI-generated images. Over several upcoming months, the tech giant will integrate the Coalition for Content Provenance and Authenticity (C2PA) standard, a system designed to track the origin and editing history of digital content, into its search, ads, and potentially YouTube services. However, it's an open question of whether a technological solution can address the ancient social issue of trust in recorded media produced by strangers.
A group of tech companies created the C2PA system beginning in 2019 in an attempt to combat misleading, realistic synthetic media online. As AI-generated content becomes more prevalent and realistic, experts have worried that it may be difficult for users to determine the authenticity of images they encounter. The C2PA standard creates a digital trail for content, backed by an online signing authority, that includes metadata information about where images originate and how they've been modified.
Google will incorporate this C2PA standard into its search results, allowing users to see if an image was created or edited using AI tools. The tech giant's "About this image" feature in Google Search, Lens, and Circle to Search will display this information when available.
OpenAI truly does not want you to know what its latest AI model is "thinking." Since the company launched its "Strawberry" AI model family last week, touting so-called reasoning abilities with o1-preview and o1-mini, OpenAI has been sending out warning emails and threats of bans to any user who tries to probe how the model works.
Unlike previous AI models from OpenAI, such as GPT-4o, the company trained o1 specifically to work through a step-by-step problem-solving process before generating an answer. When users ask an "o1" model a question in ChatGPT, users have the option of seeing this chain-of-thought process written out in the ChatGPT interface. However, by design, OpenAI hides the raw chain of thought from users, instead presenting a filtered interpretation created by a second AI model.
Nothing is more enticing to enthusiasts than information obscured, so the race has been on among hackers and red-teamers to try to uncover o1's raw chain of thought using jailbreaking or prompt injection techniques that attempt to trick the model into spilling its secrets. There have been early reports of some successes, but nothing has yet been strongly confirmed.
On Thursday, Oracle co-founder Larry Ellison shared his vision for an AI-powered surveillance future during a company financial meeting, reports Business Insider. During an investor Q&A, Ellison described a world where artificial intelligence systems would constantly monitor citizens through an extensive network of cameras and drones, stating this would ensure both police and citizens don't break the law.
Ellison, who briefly became the world's second-wealthiest person last week when his net worth surpassed Jeff Bezos' for a short time, outlined a scenario where AI models would analyze footage from security cameras, police body cams, doorbell cameras, and vehicle dash cams.
"Citizens will be on their best behavior because we are constantly recording and reporting everything that's going on," Ellison said, describing what he sees as the benefits from automated oversight from AI and automated alerts for when crime takes place. "We're going to have supervision," he continued. "Every police officer is going to be supervised at all times, and if there's a problem, AI will report the problem and report it to the appropriate person."
On Thursday, Google made Gemini Live, its voice-based AI chatbot feature, available for free to all Android users. The feature allows users to interact with Gemini through voice commands on their Android devices. That's notable because competitor OpenAI's Advanced Voice Mode feature of ChatGPT, which is similar to Gemini Live, has not yet fully shipped.
Google unveiled Gemini Live during its Pixel 9 launch event last month. Initially, the feature was exclusive to Gemini Advanced subscribers, but now it's accessible to anyone using the Gemini app or its overlay on Android.
Gemini Live enables users to ask questions aloud and even interrupt the AI's responses mid-sentence. Users can choose from several voice options for Gemini's responses, adding a level of customization to the interaction.
OpenAI finally unveiled its rumored "Strawberry" AI language model on Thursday, claiming significant improvements in what it calls "reasoning" and problem-solving capabilities over previous large language models (LLMs). Formally named "OpenAI o1," the model family will initially launch in two forms, o1-preview and o1-mini, available today for ChatGPT Plus and certain API users.
OpenAI claims that o1-preview outperforms its predecessor, GPT-4o, on multiple benchmarks, including competitive programming, mathematics, and "scientific reasoning." However, people who have used the model say it does not yet outclass GPT-4o in every metric. Other users have criticized the delay in receiving a response from the model, owing to the multi-step processing occurring behind the scenes before answering a query.
In a rare display of public hype-busting, OpenAI product manager Joanne Jang tweeted, "There's a lot of o1 hype on my feed, so I'm worried that it might be setting the wrong expectations. what o1 is: the first reasoning model that shines in really hard tasks, and it'll only get better. (I'm personally psyched about the model's potential & trajectory!) what o1 isn't (yet!): a miracle model that does everything better than previous models. you might be disappointed if this is your expectation for today's launch—but we're working to get there!"
AI-powered conversations can reduce belief in conspiracy theories by 20%. Researchers found that AI provided tailored, fact-based rebuttals to participants' conspiracy claims, leading to a lasting change in their beliefs. In one out of four cases, participants disavowed the conspiracy entirely. The study suggests that AI has the potential to combat misinformation by engaging people directly and personally.
Enlarge/ An AI-generated image featuring my late father's handwriting. (credit: Benj Edwards / Flux)
Growing up, if I wanted to experiment with something technical, my dad made it happen. We shared dozens of tech adventures together, but those adventures were cut short when he died of cancer in 2013. Thanks to a new AI image generator, it turns out that my dad and I still have one more adventure to go.
Recently, an anonymous AI hobbyist discovered that an image synthesis model called Flux can reproduce someone's handwriting very accurately if specially trained to do so. I decided to experiment with the technique using written journals my dad left behind. The results astounded me and raised deep questions about ethics, the authenticity of media artifacts, and the personal meaning behind handwriting itself.
Beyond that, I'm also happy that I get to see my dad's handwriting again. Captured by a neural network, part of him will live on in a dynamic way that was impossible a decade ago. It's been a while since he died, and I am no longer grieving. From my perspective, this is a celebration of something great about my dad—reviving the distinct way he wrote and what that conveys about who he was.
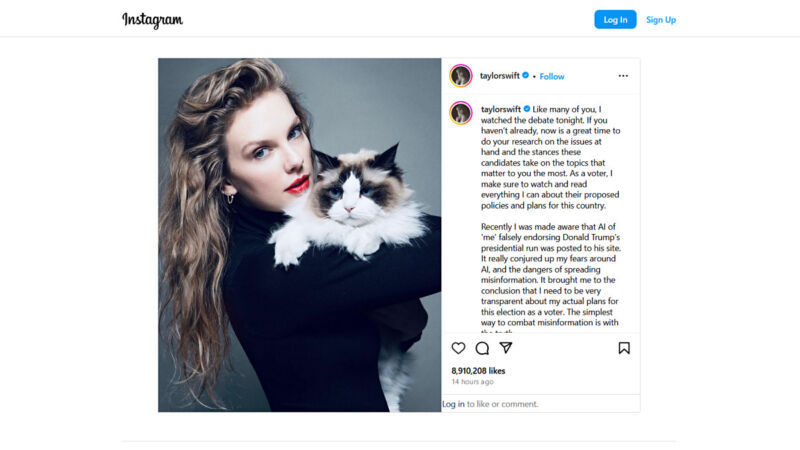
Enlarge/ A screenshot of Taylor Swift's Kamala Harris Instagram post, captured on September 11, 2024. (credit: Taylor Swift / Instagram)
On Tuesday night, Taylor Swift endorsed Vice President Kamala Harris for US President on Instagram, citing concerns over AI-generated deepfakes as a key motivator. The artist's warning aligns with current trends in technology, especially in an era where AI synthesis models can easily create convincing fake images and videos.
"Recently I was made aware that AI of ‘me’ falsely endorsing Donald Trump’s presidential run was posted to his site," she wrote in her Instagram post. "It really conjured up my fears around AI, and the dangers of spreading misinformation. It brought me to the conclusion that I need to be very transparent about my actual plans for this election as a voter. The simplest way to combat misinformation is with the truth."
In August 2024, former President Donald Trump posted AI-generated images on Truth Social falsely suggesting Swift endorsed him, including a manipulated photo depicting Swift as Uncle Sam with text promoting Trump. The incident sparked Swift's fears about the spread of misinformation through AI.
Researchers believe that cracking the brain's "neural code" could lead to AI surpassing human intelligence in capacity and speed. This neural code refers to how the brain processes sensory information and performs cognitive tasks like learning and problem-solving.
A new study examined how humans perceive different types of deception by robots, revealing that people accept some lies more than others. Researchers presented nearly 500 participants with scenarios where robots engaged in external, hidden, and superficial deceptions in medical, cleaning, and retail settings. Participants disapproved most of hidden deceptions, such as a cleaning robot secretly filming, while external lies, like sparing a patient from emotional pain, were viewed more favorably.
Researchers developed a brain-inspired AI technique using neural networks to model the challenging quantum states of molecules, crucial for technologies like solar panels and photocatalysts. This new approach significantly improves accuracy, enabling better prediction of molecular behaviors during energy transitions. By enhancing our understanding of molecular excited states, this research could revolutionize material prototyping and chemical synthesis.
When Chad Syverson loads the US Bureau of Labor Statistics website these days looking for the latest data on productivity, he does so with a sense of optimism that he hasn’t felt in ages.
The numbers for the last year or so have been generally strong for various financial and business reasons, rebounding from the early days of the pandemic. And though the quarterly numbers are notoriously noisy and inconsistent, the University of Chicago economist is scrutinizing the data to spot any early clues that AI-driven economic growth has begun.
Any effect on the current statistics, he says, will likely still be quite small and won’t be “world-changing,” so he’s not surprised that signs of AI’s impact haven’t been detected yet. But he’s watching closely, with the hope that over the next few years AI could help reverse a two-decade slump in productivity growth that is undermining much of the economy. If that does happen, Syverson says, “then it is world changing.”
The newest versions of generative AI are bedazzling, with lifelike videos, seemingly expert-sounding prose, and other all too humanlike behaviors. Business leaders are fretting over how to reinvent their companies as billions flow into startups, and the big AI companies are creating ever more powerful models. Predictions abound on how ChatGPT and the growing list of large language models will transform the way we work and organize our lives, providing instant advice on everything from financial investments to where to spend your next vacation and how to get there.
But for economists like Syverson, the most critical question around our obsession with AI is how the fledgling technology will (or won’t) boost overall productivity, and if it does, how long it will take. Think of it as the bottom line to the AI hype machine: Can the technology lead to renewed prosperity after years of stagnant economic growth?
Productivity growth is how countries become richer. Technically, labor productivity is a measure of how much a worker produces on average; innovation and technology advances account for most of its growth. As workers and businesses can make more stuff and offer more services, wages and profits go up—at least in theory, and if the benefits are shared fairly. The economy expands, and governments can invest more and get closer to balancing their budgets. For most of us, it feels like progress. It’s why, until the last few decades, most Americans believed their standard of living and financial opportunities would be greater than those of their parents and grandparents.
But when productivity growth is flat or nearly flat, the pie is no longer growing. Even a 1% annual slowdown or speedup can spell the difference between a struggling economy and a flourishing one. In the late 1990s and early 2000s, US labor productivity grew at a healthy rate of nearly 3% a year as the internet age took off. (It grew even faster, well over 3%, in the booming years after World War II). But since about 2005, productivity growth in most advanced economies has been dismal.
There are various possible culprits to blame. But there is a common theme: The seemingly brilliant technologies invented over the last two decades, from the iPhone to ubiquitous search engines to all-consuming social media, have grabbed our attention yet failed to deliver large-scale economic prosperity.
In 2016, I wrote an article titled “Dear Silicon Valley: Forget Flying Cars, Give Us Economic Growth.” I argued that while Big Tech was making breakthrough after breakthrough, it was largely ignoring desperately needed innovations in essential industrial sectors, such as manufacturing and materials. In some ways, it made perfect financial sense: Why invest in these mature, risky businesses when a successful social media startup could net billions?
But such choices came with a cost in sluggish productivity growth. While a few in Silicon Valley and elsewhere became fabulously wealthy, at least some of the political chaos and social unrest experienced in a number of advanced economies over the last few decades can be blamed on the failure of technology to increase financial opportunities for many workers and businesses and expand vital sectors of the economy across different regions.
Some preach patience: The breakthroughs will take time to work through the economy but once they do, watch out! That’s probably true. But so far, the result is a deeply divided country where the techno-optimism—and immense wealth—oozing out from Silicon Valley seem relevant to only a few.
It’s still too early to know how things will shake out this time around—whether generative AI is truly a once-in-a-century breakthrough that will spur a return to financial good times or whether it will do little to create real widespread prosperity. Put another way, will it be like the harnessing of electricity and the invention of the electric motor, which led to an industrial boom, or more like smartphones and social media, which have consumed our collective consciousness without bringing significant economic growth?
For AI, particularly generative models, to have a greater economic impact than other digital advances over the last few decades, we will need to use the technology to transform productivity across the economy—even in how we generate new ideas. It’s a huge undertaking and won’t happen overnight, but we’re at a critical inflection point. Do we start down that path to broadly increased prosperity, or do the creators of today’s breakthrough AI continue to ignore the vast potential of the technology to truly improve our lives?
Cold water on (over)heated speculation
A series of studies over the last year show how generative AI can boost productivity for people doing various jobs. Economists at Stanford and MIT have found that those working in call centers are 14% more productive when using AI conversational assistance; notably, there was a 35% improvement in the performance of inexperienced and low-skilled workers. Another study showed that software engineers could code twice as fast with the technology’s help.
Last year, Goldman Sachs calculated that generative AI would likely boost overall productivity growth by 1.5 percentage points every year in developed countries and increase global GDP by $7 trillion over 10 years. And some predict that the effects will appear soon.
Anton Korinek, an economist at the University of Virginia, says the added growth has not yet shown up in the productivity numbers because it takes time for generative AI to diffuse throughout the economy. But he predicts a 1% to 1.5% boost to US productivity by next year. And if there continue to be breakthroughs in generative AI models—think ChatGPT5—the eventual impact could be “significantly higher,” says Korinek.
Not everyone is so bullish. Daron Acemoglu, an MIT economist, says his calculations are a “corrective against those who say that within five years the entire US economy is going to be transformed.” As he sees it, “generative AI could be a big deal. We don’t know yet. But if it is, we’re not going to see transformative effects within 10 years—it’s too soon. It will take time.”
MIT’s Daron Acemoglu calculates that any productivity growth from generative AI will be modest over the next 10 years, and far less than many predict.
JARED CHARNEY/MIT
In April, Acemoglu posted a paper predicting that generative AI’s impact on total factor productivity (TFP)—the portion that specifically reflects the contribution from innovation and new technologies—will be around 0.6% in total over 10 years, far less than Goldman Sachs and others expect. For decades, TFP growth has been sluggish, and he sees generative AI doing little to significantly reverse the trend—at least in the short term.
Acemoglu says he expects relatively modest productivity gains from generative AI because its Big Tech creators have largely had a narrow focus on using AI to replace people with automation and to enable “online monetization” of search and social media. To have a greater impact on productivity, he argues, AI needs to be useful for a far broader portion of the workforce and relevant for more parts of the economy. Critically, it needs to be used to create new types of jobs, not just to replace workers.
Acemoglu argues that generative AI could be used to expand the capabilities of workers by, for example, supplying real-time data and reliable information for many types of jobs. Think of an intelligent AI agent, but one versed on the intricacies of, say, factory-floor production. Yet, he writes, “these gains will remain elusive unless there is a fundamental reorientation of the [tech] industry, including perhaps a major change in the architecture of the most common generative AI models.”
It’s tempting to think that perhaps it’s simply a matter of tweaking today’s large foundation models with the appropriate data to make them widely useful for various industries. But in fact, we will need to rethink the models and how they can be more effectively deployed in a far broader range of uses.
Producing progress
Take manufacturing. For many years, it was one of the important sources of productivity gains in the US economy. It still accounts for much of the country’s R&D. And recent increases in automation and the use of industrial robots might suggest that manufacturing is becoming more productive—but that has not been the case. For somewhat mysterious reasons, productivity in US manufacturing has been a disaster since about 2005, which has played an outsize role in the overall productivity slowdown.
The promise of generative AI in reviving productivity is that it could help integrate everything from initial materials and design choices to real-time data from sensors embedded in production equipment. Multimodal capabilities could allow a factory worker to, say, snap a picture of a problem and ask the AI model for a solution based on the image, the company’s operating manual, any relevant regulatory guidelines, and vast amounts of real-time data from the machinery.
That’s the vision, at least.
The reality is that efforts to deploy today’s foundation models in design and manufacturing are in their very early days. Use of AI so far has been limited to “narrow domains,” says Faez Ahmed, an MIT mechanical engineer specializing in machine learning—think scheduling maintenance on the basis of data from a particular piece of equipment. In contrast, generative AI models could, in theory, be broadly useful for everything from improving initial designs with real data to monitoring the steps of a production process to analyzing performance data on the factory floor.
In a paper released in March, a team of MIT economists and mechanical engineers (including Acemoglu and Ahmed) identified numerous opportunities for generative AI in design and manufacturing, before concluding that “current [generative AI] solutions cannot accomplish these goals due to several key deficiencies.” Chief among the shortcomings of ChatGPT and other AI models are their inability to supply reliable information, their lack of “relevant domain knowledge,” and their “unawareness of industry-standards requirements.” The models are also ill designed to handle the spatial problems on manufacturing floors and the various types of data created by production equipment, including old machinery.
The biggest difficulty is that existing generative AI models lack the appropriate data, says Ahmed. They are trained on data scraped from the internet, and “it’s a lot more about cats and dogs and multimedia content rather than how do you actually operate a lathe machine,” he says. “The reason these models perform relatively poorly on manufacturing tasks is that they’ve never seen manufacturing tasks.”
Gaining access to such data is tricky because much of it is proprietary. “Some people are really scared that a model will take my data and run away with it,” he says. A related problem is that manufacturing requires precision and, often, adherence to strict industry or government guidelines. “If the systems are not precise and not trustworthy, people are less likely to use them,” he says. “And it’s a chicken-and-egg problem: because the models are not precise; because there is no data.”
The MIT researchers called for a “next generation” of AI models that would be tailored to manufacturing. But there is a problem: Creating a manufacturing-relevant AI that takes advantage of the power of foundation models will require close collaboration between industry and AI companies, and that’s something still in its nascent stage.
The lack of progress so far, says Ranveer Chandra, managing director of research for industry at Microsoft Research, “is not because people are not interested, or they don’t see the business value.” The holdup is finding ways to secure the data and make sure it is in a useful form and provides relevant answers to specific manufacturing questions.
Microsoft is pursuing several strategies. One is asking the foundation model to base its answers on a company’s proprietary data—say, a company’s operations manual and production data. A far more difficult but appealing alternative is fine-tuning the underlying architecture of the model to better suit manufacturing. Yet another approach: so-called small language models, which also can be trained specifically on the data from a company. Since they are smaller than foundation models like GPT-4, they need less computational power and can be more targeted to specific manufacturing tasks.
“But this is all research at this point,” says Chandra. “Have we solved it? Not yet.”
A gold mine of new ideas
Using AI to boost scientific discovery and innovation could have the greatest overall productivity impact over the long term. Economists have long recognized new ideas as the source of long-term growth, and the hope is that new AI tools could turbocharge the search for them. While improving the efficiency of, say, a call center worker could mean a one-time jump in productivity in that business, using AI to improve the process of inventing new technologies and business practices—to create useful new ideas—could lead to an enduring increase in the rate of economic growth as it reshapes the innovation process and the way research is done.
There are already tantalizing clues to AI’s potential.
Most notably, Google DeepMind, which defines its mission as “solving some of the hardest scientific and engineering challenges of our time,“ says more than 2 million users have accessed its deep-learning AI system to predict protein folding. Many drugs target a particular protein, and knowing the 3D structure of such proteins—something that traditionally takes painstaking lab analysis—could be an invaluable step in creating new medicines. In May, Google released AlphaFold 3, claiming it “predicts the structure and interactions of all of life’s molecules“ to help identify how various biomolecules alter each other, providing an even more powerful guide for finding new drugs.
Creators of AI models, including DeepMind and Microsoft Research, are also working on other problems in biology, genomics, and materials science. The hope is that generative AI could help scientists glean key information from the vast data sets common in these fields, making it easier and faster to, say, discover new drugs and materials.
We badly need such a boost. A few years ago, a team of leading economists wrote a paper called “Are Ideas Getting Harder to Find?“ and found that it takes more and more researchers and money to find the kinds of new ideas that are key to sustaining technology advances. The problem, in technical terms, is that research productivity—the output of ideas given the number of scientists—is falling rapidly. In other words—yes, ideas are getting harder to find. We’ve generally kept up by adding more researchers and investing more in R&D, but overall US research productivity itself is in a deep decline.
To uphold Moore’s Law, which predicts that the number of transistors on a chip will double roughly every two years, the semiconductor industry needs 18 times more researchers than it had in the early 1970s. Likewise, it takes far more scientists to come up with roughly the same number of new drugs than it did a few decades ago.
Could AI dream up safe and effective new drugs and find astonishing new materials for computation and clean energy?
John Van Reenen, a professor at the London School of Economics and one of the authors of the paper, knows it’s still too early to see any real change in the productivity data from AI, but he says, “The hope is that [it] can make some difference.” AlphaFold is “a poster child” for how AI can change science, he says, and “the question is whether this can go from anecdotes to something more systematic.”
The ambition is not only to supply various tools that will make the lives of scientists easier, like automated literature search, but for AI itself to come up with original and useful scientific ideas that would otherwise evade researchers. In that vision, AI dreams up new compounds that are more effective and safer than existing drugs, and astonishing materials that expand the possibilities of computation and clean energy. The goal is especially compelling because the universe of potential molecules is virtually unlimited. Navigating such a nearly infinite space and exploring the vast number of possibilities is what machine learning is especially good at.
But don’t hold your breath for AI’s Thomas Edison moment. Though the scientific popularity of AlphaFold has raised expectations for the potential of AI, it is still very early days in turning the research into actual products—whether new drugs or novel materials. In a recent analysis, a team of MIT scientists put it this way: “Generative AI has undoubtedly broadened and accelerated the early stages of chemical design. However, real-world success takes place further downstream, where the impact of AI has been limited so far.”
In fact, the process of turning the intriguing scientific advances in using AI into actual, useful stuff is still very much in its infancy.
It’s a material world
Perhaps nowhere is the excitement over AI’s potential to transform research greater than in the often neglected field of materials discovery. The world desperately needs better materials. We need them for cheaper and more powerful batteries and solar cells, and for new types of catalysts that would make cleaner industrial processes possible; we need practical high-temperature superconductors to revolutionize how we transport electricity.
So when DeepMind said it had used deep learning to discover some 2.2 million inorganic crystals—including some 380,000 predicted to be stable and promising candidates for actual synthesis—the report was greeted with great excitement, especially in the AI community. A materials revolution! It seemed like a gold mine of new stuff—“an order-of-magnitude expansion in stable materials known to humanity,” wrote the DeepMind researchers in Nature. The DeepMind database, called GNoME (an acronym for “graph networks for materials exploration”), is “equivalent to 800 years of knowledge,” according to the company’s media release.
But in the months after the paper, some researchers disputed the hype. Materials scientists at the University of California, Santa Barbara, published a paper in which they reported finding “scant evidence“ that any of the structures in the DeepMind database fulfilled the “trifecta of novelty, credibility, and utility.“
For some tasked with finding new materials, the huge databases of possible inorganic crystals, many of which may not be stable enough to actually exist, seems like a distraction. “If you spam us with 400,000 new materials and we don’t even know which one of those are realistic, then we don’t know which one of those will be good for a battery or catalyst or whatever you want to make them. Then this information is not useful,” says Leslie Schoop, a chemist at Princeton who co-wrote a paper describing the challenges of using automation and AI in materials discovery and synthesis.
To be clear, this doesn’t mean that AI won’t prove to be important in materials science and chemistry. Even critics say they are excited by the long-term possibilities. But the criticisms hint at just how early we are in using AI to tackle the daunting task of materials discovery and making it a reliable tool for finding new compounds that are better than existing ones.
It’s extremely expensive and time-consuming to make and test any possible new material. What industrial researchers really need are reliable clues pointing to materials that are predictably stable, can be synthesized, and likely have intriguing properties, including being cheap to make.
The GNoME database probably includes interesting compounds, say its DeepMind scientific creators. But they acknowledge it’s only a preliminary step in showing how AI could help in materials discovery. Much work remains to broaden its usefulness.
Ekin Dogus Cubuk, a Google research scientist and coauthor of the Nature paper, describes the work it reports as an advance in predicting a large number of possible inorganic crystals that are stable, based on quantum-mechanical calculations, at absolute zero, where atomic motion comes to a standstill. Such predictions could be useful for those running computational simulations of new materials—a very early stage of materials discovery.
But, he says, machine learning has not yet been used to predict crystals that are stable at room temperature. After that is achieved comes the goal of using AI to predict how structures can be synthesized in the lab, and eventually how to make them at larger scale. All that must be done before machine learning can really transform the lengthy and expensive process of coming up with new materials, he says.
For those hoping that AI models could boost economic productivity by transforming science, one lesson is clear: Be patient. Such scientific advances could well have an impact one day. But it will take time—likely measured in decades.
The Solow paradox
As senior vice president for research, technology, and society at Google, James Manyika is unsurprisingly enthusiastic about the huge potential for AI to transform the economy. But he is far from an unabashed cheerleader, mindful of the lessons gleaned from his years of studying how technologies affect productivity.
Before joining Google in 2022, Manyika spent several decades as a consultant, a researcher, and finally chairman of the McKinsey Global Institute, the economic research arm of the consulting giant. At McKinsey he became a leading authority on the link between technology and economic growth, and he counts Robert Solow—the MIT economist who won the 1987 Nobel Prize for explaining how technological advances are the main source of productivity growth—as an early mentor.
Among the lessons from Solow, who died late last year at the age of 99, is that even powerful technologies can take time to affect economic growth. In 1987, Solow quipped: “You can see the computer age everywhere but in the productivity statistics.” At the time, information technology was undergoing a revolution, most visible with the introduction of the personal computer. Yet productivity, as measured by economists, was sluggish. This became known as the Solow paradox. It wasn’t until the late 1990s, decades after the birth of the computer age, that productivity growth began to finally pick up.
History has taught Manyika to be circumspect in predicting how and when the overall economy will feel the impact of generative AI. “I don’t have a time frame,” he says. “The estimates [of productivity gains] are generally spectacularly large, but when it comes to a question of time frame, I say ‘It depends.’”
Specifically, he says it depends on what economists call “the pace of diffusion”—basically, how quickly users take up the technology both within sectors and across sectors. It also hinges on the ability of various users, especially businesses in the largest sectors of the economy, to “[reorganize] functions and tasks and processes to capitalize on the technology” and to make their operations and workers more productive. Without those pieces, we’ll be stuck in “Solow paradox land,” says Manyika.
“Tech can do whatever tech wants, and it doesn’t really matter from a labor productivity standpoint,” he says, since its workforce is relatively small. “We have to have changes happen in the largest sectors before we can start to see productivity gains at an economy level.”
“By the beginning of the next decade, the shift to AI could become a leading driver of global prosperity,” they wrote, because it has the potential to affect “just about every aspect of human and economic activity.” They added: “If these innovations can be harnessed, AI could reverse the long-term declines in productivity growth that many advanced economies now face.” But it’s a big if, they acknowledged, saying it “won’t happen on its own” and will require “positive policies that foster AI’s most productive uses.”
Google’s James Manyika says AI’s impact on the economy is potentially huge but will depend on how quickly business users adopt and deploy the technology.
ARNO MIKKOR/WIKIMEDIA COMMONS
The call for policies is a recognition of the immense task ahead, and an acknowledgment that even giant AI companies like Google can’t do it alone. It will take widespread investments in infrastructure and additional innovations by governments and businesses.
Companies ranging from small startups to large corporations will need to take the foundation models, such as Google’s Gemini, and “tailor them for their own applications in their own environments in their own domains,” says Manyika. In a few cases, he says, Google has done some of the tailoring, “because it’s kind of interesting to us.”
For example, Google released Med-Gemini in May, using the multimodal abilities of its foundation model to help in a wide range of medical tasks, including making diagnostic decisions based on imaging, videos of surgeries, and information in electronic health records. Now, says Manyika, it’s up to health-care practitioners and researchers to “think how to apply this, because we’re not in the health-care business in that way.” But, he says, “it is giving them a running start.”
But therein lies the great challenge going forward if AI is to transform the economy.
Despite the fanfare around generative AI and the billions of dollars flowing to startups around the technology, the speed of its diffusion into the business world is not all that encouraging. According to a survey of thousands of businesses by the US Census Bureau, released in March, the proportion of firms using AI rose from about 3.7% in September 2023 to 5.4% this February, and it is expected to reach around 6.6% by the end of the year. Most of this uptake has come in sectors like finance and technology. Industries like construction and manufacturing are virtually untouched. The main reason for the lack of interest: what most companies see as the “inapplicability” of AI to their business.
For many companies, particularly small ones, it still takes a huge leap of faith to bet on AI and invest the money and time it takes to reorganize business functions around it. In addition to not seeing any value in the technology, lots of business leaders have ongoing questions over the reliability of the generative AI models—hallucinations are one thing in the chat room but quite something else on the manufacturing floor or in a hospital ER. They also have concerns over data privacy and the security of proprietary information. Without AI models more tailored to the needs of various businesses, it’s likely that many will stay on the sidelines.
Meanwhile, Silicon Valley and Big Tech are obsessed with intelligent agents and with videos vreated by generative AI; individual and corporate fortunes are being amassed on the promise of turbocharging smartphones and internet searches. As in the early 2010s, much of the rest of the economy is being left out. They’re not benefiting either from the financial rewards of the technology or from its ability to expand large sectors and make them more productive.
Maybe it’s too much to expect Big Tech to change, to suddenly care about using its massive power to benefit sectors such as manufacturing. After all, Big Tech does what it does.
And it won’t be easy for AI companies to rethink their huge foundation models for such real-world problems. They will need to engage with industry experts from a wide variety of sectors and respond to their needs. But the reality is that the big AI companies are the only organizations with the vast computational power to run today’s foundation models and the talent to invent the next generations of the technology.
So like it or not, in dominating the field, they have taken on the responsibility for its broad applicability. Whether they will shoulder that responsibility for all our benefit or (once again) ignore it for the siren song of wealth accumulation will eventually reveal itself—perhaps initially in those often nearly indecipherable quarterly numbers from the US Bureau of Labor Statistics website.
Correction: we updated the description of the Princeton paper
A new machine learning model, AutMedAI, can predict autism in children under two with nearly 80% accuracy, offering a promising tool for early detection and intervention. The model analyzes 28 parameters available before 24 months, such as age of first smile and eating difficulties, to identify children likely to have autism. Early diagnosis is crucial for optimal development, and further validation of the model is underway.
The US Department of Homeland Security (DHS) is looking into ways it might use facial recognition technology to track the identities of migrant children, “down to the infant,” as they age, according to John Boyd, assistant director of the department’s Office of Biometric Identity Management (OBIM), where a key part of his role is to research and develop future biometric identity services for the government.
As Boyd explained at a conference in June, the key question for OBIM is, “If we pick up someone from Panama at the southern border at age four, say, and then pick them up at age six, are we going to recognize them?”
Facial recognition technology (FRT) has traditionally not been applied to children, largely because training data sets of real children’s faces are few and far between, and consist of either low-quality images drawn from the internet or small sample sizes with little diversity. Such limitations reflect the significant sensitivities regarding privacy and consent when it comes to minors.
According to Syracuse University’s Transactional Records Access Clearinghouse (TRAC), 339,234 children arrived at the US-Mexico border in 2022, the last year for which numbers are currently available. Of those children, 150,000 were unaccompanied—the highest annual number on record. If the face prints of even 1% of those children were in OBIM’s craniofacial structural progression initiative, the resulting data set would dwarf nearly all existing data sets of real children’s faces used for aging research.
Prior to publication of this story Boyd told MIT Technology Review that to the best of his knowledge, the agency has not yet started collecting data under the program, but he adds that as “the senior executive,” he would “have to get with [his] staff to see.” He could only confirm that his office is “funding” it. Despite repeated requests, Boyd did not provide any additional information. After publication, DHS denied that it had plans to collect facial images from minors under 14.
Boyd described recent “rulemaking” at “some DHS components,” or sub-offices, that have removed age restrictions on the collection of biometric data. US Customs and Border Protection (CBP), the US Transportation Security Administration, and US Immigration and Customs Enforcement declined to comment before publication. US Citizenship and Immigration Services (USCIS) did not respond to multiple requests for comment. OBIM referred MIT Technology Review back to DHS’s main press office.
DHS did not comment on the program prior to publication, but sent an emailed statement afterwards: “The Department of Homeland Security uses various forms of technology to execute its mission, including some biometric capabilities. DHS ensures all technologies, regardless of type, are operated under the established authorities and within the scope of the law. We are committed to protecting the privacy, civil rights, and civil liberties of all individuals who may be subject to the technology we use to keep the nation safe and secure.”
The agency later noted “DHS does not collect facial images from minors under 14, and has no current plans to do so for either operational or research purposes,” walking back Boyd’s statements.
Boyd spoke publicly about the plan in June at the Federal Identity Forum and Exposition, an annual identity management conference for federal employees and contractors. But close observers of DHS that we spoke with—including a former official, representatives of two influential lawmakers who have spoken out about the federal government’s use of surveillance technologies, and immigrants’ rights organizations that closely track policies affecting migrants—were unaware of any new policies allowing biometric data collection of children under 14.
That is not to say that all of them are surprised. “That tracks,” says one former CBP official who has visited several migrant processing centers on the US-Mexico border and requested anonymity to speak freely. He says “every center” he visited “had biometric identity collection, and everybody was going through it,” though he was unaware of a specific policy mandating the practice. “I don’t recall them separating out children,” he adds. “The reports of CBP, as well as DHS more broadly, expanding the use of facial recognition technology to track migrant children is another stride toward a surveillance state and should be a concern to everyone who values privacy,” Justin Krakoff, deputy communications director for Senator Jeff Merkley of Oregon, said in a statement to MIT Technology Review. Merkley has been an outspoken critic of both DHS’s immigration policies and of government use of facial recognition technologies.
Beyond concerns about privacy, transparency, and accountability, some experts also worry about biometric technologies targeting a population that has little recourse to provide—or withhold—consent.
“If you arrive at a border … and you are faced with the impossible choice of either: get into a country if you give us your biometrics, or you don’t,” says Petra Molnar, author of The Walls Have Eyes: Surviving Migration in the Age of AI, “that completely vitiates informed consent,” she adds.
This question becomes even more challenging when it comes to children, says Ashley Gorski, a senior staff attorney with the American Civil Liberties Union. “There’s a significant intimidation factor, and children aren’t as equipped to consider long-term risks.”
Murky new rules
The Office of Biometric Identity Management, previously known as the US Visitor and Immigrant Status Indicator Technology Program (US-VISIT), was created after 9/11 with the specific mandate of collecting biometric data—initially only fingerprints and photographs—from all non-US citizens who sought to enter the country.
Since then, DHS has begun collecting face prints, iris scans, and even DNA, among other modalities. It is also testing new ways of gathering this data—including through contactless fingerprint collection, which is currently deployed at five sites on the border, as Boyd shared in his conference presentation.
Since 2023, CBP has been using a mobile app, CBP One, for asylum seekers to submit biometric data even before they enter the United States; users are required to take selfies periodically to verify their identity. The app has been riddled with problems, including technical glitches and facial recognition algorithms that are unable to recognize darker-skinned people. This is compounded by the fact that not every asylum seeker has a smartphone.
Then, just after crossing into the United States, migrants submit to collection of more biometric data, including DNA. For a sense of scale, a recent report from Georgetown Law School’s Center on Privacy and Technology found that CBP has added 1.5 million DNA profiles, primarily from migrants crossing the border, to law enforcement databases since it began collecting DNA “from any person in CBP custody subject to fingerprinting” in January 2020, per rules enacted by the Department of Justice under the Trump administration. The researchers noted that an over-representation of immigrants—the majority of whom are people of color—in a DNA database used by law enforcement could subject them to over-policing and lead to other forms of bias.
Generally, these programs only require information from individuals aged 14 to 79. DHS attempted to change this back in 2020, with proposed rules for USCIS and CBP that would have expanded biometric data collection dramatically, including by age. (USCIS’s proposed rule would have doubled the number of people from whom biometric data would be required, including any US citizen who sponsors an immigrant.) But the USCIS rule was withdrawn in the wake of the Biden administration’s new “priorities to reduce barriers and undue burdens in the immigration system.” Meanwhile, for reasons that remain unclear, the proposed CBP rule was never enacted.
This would make it appear “contradictory” if DHS were to begin collecting the biometric data of children under 14, says Dinesh McCoy, a staff attorney with Just Futures Law, an immigrant rights group that tracks surveillance technologies.
Neither Boyd nor DHS’s media office would confirm which specific policy changes he was referring to in his presentation, though MIT Technology Review has identified a 2017 memo, issued by then-Secretary of Homeland Security John F. Kelly, that encouraged DHS components to remove “age as a basis for determining when to collect biometrics.” The DHS’s Office of the Inspector General (OIG) quoted a DHS senior official as to this memo as the “overarching policy for biometrics at DHS” in a September 2023 report, though none of the press offices MIT Technology Review contacted—including the main DHS press office, OIG, and OBIM, among others—would confirm on the recordwhether this was still the relevant policy; we have not been able to confirm any related policy changes since then.
The OIG audit also found a number of fundamental issues related to DHS’s oversight of biometric data collection and use—including that its 10-year strategic framework for biometrics, covering 2015 to 2025, “did not accurately reflect the current state of biometrics across the Department, such as the use of facial recognition verification and identification.” Nor did it provide clear guidance for the consistent collection and use of biometrics across DHS, including age requirements.
Do you have any additional information on DHS’s craniofacial structural progression initiative? Please reach out with a non-work email to tips@technologyreview.com or securely on Signal at 626.765.5489.
Some lawyers allege that changing the age limit for data collection via department policy, not by a federal rule, which requires a public comment period, would be problematic. McCoy, for instance, says any lack of transparency here amplifies the already “extremely challenging” task of “finding [out] in a systematic way how these technologies are deployed”—even though that is key for accountability.
Advancing the field
At the identity forum and in a subsequent conversation, Boyd explained that the initiative is meant to advance the development of effective FRT algorithms. Boyd leads OBIM’s Future Identity team, whose mission is to “research, review, assess, and develop technology, policy, and human factors that enable rapid, accurate, and secure identity services” and to make OBIM “the preferred provider for identity services within DHS.”
Driven by high-profile cases of missing children, there has long been interest in understanding how children’s faces age. At the same time, there have been technical challenges to doing so, both preceding FRT and with it.
At its core, facial recognition identifies individuals by comparing the geometry of various facial features in an original face print with subsequent images. Based on this comparison, a facial recognition algorithm assigns a percentage likelihood that there is a match.
But as children grow and develop, their bone structure changes significantly, making it difficult for facial recognition algorithms to identify them over time. (These changes tend to be even more pronounced in children under 14. In contrast, as adults age, the changes tend to be in the skin and muscle, and have less variation overall.) More data would help solve this problem, but there is a dearth of high-quality data sets of children’s faces with verifiable ages.
“What we’re trying to do is to get large data sets of known individuals,” Boyd tells MIT Technology Review. That means taking high-quality face prints “under controlled conditions where we know we’ve got the person with the right name [and] the correct birth date”—or, in other words, where they can be certain about the “provenance of the data.”
For example, one data set used for aging research consists of 305 celebrities’ faces as they aged from five to 32. But these photos, scraped from the internet, contain too many other variables—such as differing image qualities, lighting conditions, and distances at which they were taken—to be truly useful. Plus, speaking to the provenance issue that Boyd highlights, their actual ages in each photo can only be estimated.
Another tactic is to use data sets of adult faces that have been synthetically de-aged. Synthetic data is considered more privacy-preserving, but it too has limitations, says Stephanie Schuckers, director of the Center for Identification Technology Research (CITeR). “You can test things with only the generated data,” Schuckers explains, but the question remains: “Would you get similar results to the real data?”
(Hosted at Clarkson University in New York, CITeR brings together a network of academic and government affiliates working on identity technologies. OBIM is a member of the research consortium.)
Schuckers’s team at CITeR has taken another approach: an ongoing longitudinal study of a cohort of 231 elementary and middle school students from the area around Clarkson University. Since 2016, the team has captured biometric data every six months (save for two years of the covid-19 pandemic), including facial images. They have found that the open-source face recognition models they tested can in fact successfully recognize children three to four years after they were initially enrolled.
But the conditions of this study aren’t easily replicable at scale. The study images are taken in a controlled environment, all the participants are volunteers, the researchers sought consent from parents and the subjects themselves, and the research was approved by the university’s Institutional Review Board. Schuckers’s research also promises to protect privacy by requiring other researchers to request access, and by providing facial datasets separately from other data that have been collected.
What’s more, this research still has technical limitations, including that the sample is small, and it is overwhelmingly Caucasian, meaning it might be less accurate when applied to other races.
Schuckers says she was unaware of DHS’s craniofacial structural progression initiative.
Far-reaching implications
Boyd says OBIM takes privacy considerations seriously, and that “we don’t share … data with commercial industries.” Still, OBIM has “approximately 140” government partners with which it shares and receives information, according to a report by the Government Accountability Office, which has criticized it for poorly documenting its agreements.
Even if the data does stay within the federal government, OBIM’s findings regarding the accuracy of FRT for children over time could neverthelessinfluence how—and when—the rest of the government collects biometric data, as well as whether the broader facial recognition industry may also market its services for children. (Indeed, Boyd says sharing “results,” or the findings of how accurate FRT algorithms are, is different than sharing the data itself.)
That this technology is being targeted at people who are offered fewer privacy protections than would be afforded to US citizens is just part of the wider trend of using people from the developing world, whether they are migrants coming to the border or civilians in war zones, to help improve new technologies.
In fact, Boyd previously helped advance the Department of Defense’s biometric systems in Iraq and Afghanistan, where he acknowledged that individuals were subject to different rules than would have been applied in many other contexts, despite the incredibly high stakes. Biometric data collected in those war zones—in some areas, from every fighting-age male—was used toidentify and target insurgents, and being misidentified could mean death.
These projects subsequently played a substantial role in influencing the expansion of biometric data collection by the Department of Defense, which now happens globally. And architects of the program, like Boyd, have taken important roles in expanding the use of biometrics at other agencies.
“It’s not an accident” that this development happens in the context of border zones, says Molnar. Borders are “the perfect laboratory for tech experimentation, because oversight is weak, discretion is baked into the decisions that get made … it allows the state to experiment in ways that it wouldn’t be allowed to in other spaces.”
But, she notes, “just because it happens at the border doesn’t mean that that’s where it’s going to stay.”
Correction: An earlier version of this story said the DHS had plans to collect facial data from children under 14 , based on remarks by John Boyd. Following publication, the department said it had no current plans to do so. The story has also been updated to reflect DHS’s additional comments and clarifications throughout.
Do you have any additional information on DHS’s craniofacial structural progression initiative? Please reach out with a non-work email to tips@technologyreview.com or securely on Signal at 626.765.5489.
New research reveals that large language models (LLMs) like ChatGPT cannot learn independently or acquire new skills without explicit instructions, making them predictable and controllable. The study dispels fears of these models developing complex reasoning abilities, emphasizing that while LLMs can generate sophisticated language, they are unlikely to pose existential threats. However, the potential misuse of AI, such as generating fake news, still requires attention.
Researchers discovered that humans can detect water temperature through its sound. Using machine learning, they analyzed how people perceive thermal properties via auditory cues.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}